《百面机器学习》读书笔记(十三)-生成式对抗网络
本文共 1088 字,大约阅读时间需要 3 分钟。
全部笔记的汇总贴:
一、初始GANs的秘密
- ★☆☆☆☆ 简述GANs的基本思想和训练过程。
GANs的主要框架包括生成器(Generator)和判别器(Discriminator)两个部分。其中,生成器用于合成“假”样本,判别器用于判断输入的样本是真实的还是合成的。具体来说,生成器从先验分布中采得随机信号,经过神经网络的变换,得到模拟样本;判别器既接收来自生成器的模拟样本,也接收来自实际数据集的真实样本,但我们并不告诉判别器样本来源,需要它自己判断。生成器和判别器是一对“冤家”,置身于对抗环境中,生成器尽可能造出样本迷惑判别器,而判别器则尽可能识别出来自生成器的样本。然而,对抗不是目的,在对抗中让双方能力各有所长才是目的。理想情况下,生成器和判别器最终能达到一种平衡,双方都臻于完美,彼此都没有更进一步的空间。
GANs采用对抗策略进行模型训练,一方面,生成器通过调节自身参数,使得其生成的样本尽量难以被判别器识别出是真实样本还是模拟样本;另一方面,别器通过调节自身参数,使得其能尽可能准确地判别出输入样本的来源。具体训练时,采用生成器和判别器交替优化的方式。
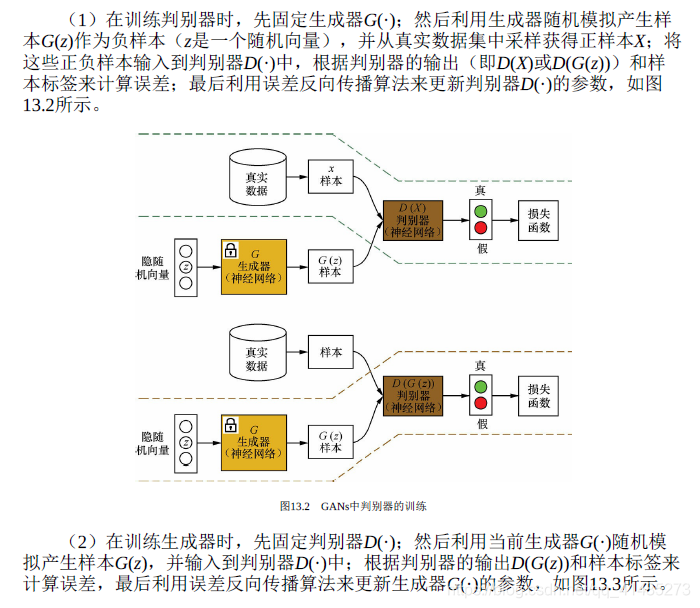
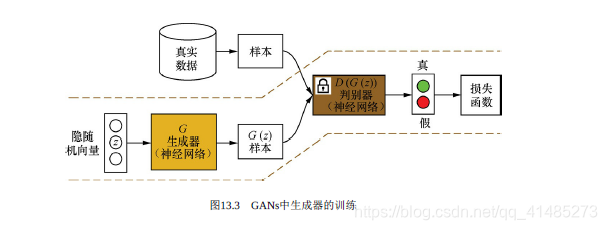
- ★★★☆☆ GANs的值函数。



- ★★☆☆☆ GANs如何避开大量概率推断计算?

- ★★★★☆ GANs在实际训练中会遇到什么问题?


二、WGAN:抓住低维的幽灵
- ★★★☆☆ GANs的陷阱:原GANs中存在的哪些问题制约模型训练效果。


- ★★★★☆ 破解武器:WGAN针对前面问题做了哪些改进?什么是Wasserstein距离?
通俗的解释,接着“布网”的比喻,现在生成器不再“布网”,改成“定位追踪”了,不管真实分布藏在哪个低维子空间里,生成器都能感知它在哪,因为生成器只要将自身分布稍做变化,就会改变它到真实分布的推土机距离;而JS距离是不敏感的,无论生成器怎么变化,JS距离都是一个常数。因此,使用推土机距离,能有效锁定低维子空间中的真实数据分布。

- ★★★★★ WGAN之道:怎样具体应用Wasserstein距离实现WGAN算法?


三、DCGAN:当GANs遇上卷积
- ★★★☆☆ 在生成器和判别器中应该怎样设计深层卷积结构?




四、ALI:包揽推断业务
- ★★★☆☆ 生成网络和推断网络的融合。


五、IRGAN:生成离散样本
- ★★★★★ 用GAN产生负样本。



六、SeqGAN:生成文本序列
- ★★☆☆☆ 如何构建生成器,生成文字组成的序列来表示句子?

- ★★★★★ 训练序列生成器的优化目标通常是什么?GANs框架下有何不同?



- ★★★★★ 有了生成器的优化目标,怎样求解它对生成器参数的梯度?


下一章传送门:
转载地址:http://copq.baihongyu.com/
你可能感兴趣的文章